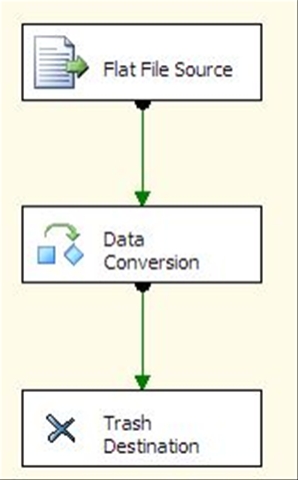
Here i have described some the useful Fiscal and Calendar NamedSet
- Last Years
- Last Quartes
- Last Months
- Current Month
- LastDays
- Current Fiscal Months
- Fiscal Months
- Last Calendar Month
1. Last Years:
ORDER(
LASTPERIODS(3, StrToMember("
[Date].[Time].[Year].&["
+ Format(Now(),"yyyy")
+"]"
))
,[Date].[Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), BDESC)
2. Last Quarters
ORDER(
LASTPERIODS(4, StrToMember("[Date].[Time].[Year].&["
+ Format(Now(), "yyyy")
+ "].&["
+ Format(Now(), "yyyy")
+ "]&["
+ cstr(datepart( "q", Now()))
+ "]"))
,[Date].[Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), BDESC)
3.LastMonthsORDER(
LASTPERIODS(6, StrToMember("
[Date].[Time].[Year].&["
+ Format(Now(),"yyyy")
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ cstr(datepart("q", Now()))
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ Format(Now(),"MM")
+"]"
))
,[Date].[Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), BDESC)
4.Current Month:
StrToMember("
[Date].[Time].[Year].&["
+ Format(Now(),"yyyy")
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ cstr(datepart("q", Now()))
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ Format(Now(),"MM")
+"]"
)
5. LastDays
ORDER(
LASTPERIODS(30, StrToMember("
[Date].[Time].[Year].&["
+ Format(Now(), "yyyy")
+ "].&["
+ Format(Now(), "yyyy")
+ "]&["
+ cstr(datepart( "q", Now()))
+ "].&["
+ Format(Now(), "yyyy")
+ "]&["
+ Format(Now(), "MM")
+ "].&["
+ Format(Now(), "dd")
+ "]"
))
,[Date].[Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), BDESC)
6.Current Fiscal Months
ORDER(
StrToMember("[Date].[Fiscal Time].[Fiscal Year].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[1].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[1]")
:
StrToMember("[Date].[Fiscal Time].[Fiscal Year].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN CSTR(CINT(DATEPART("q", Now())) - 1)
ELSE CSTR(CINT(DATEPART("q", Now())) + 3) END + "].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[" +
CASE WHEN Format(Now(),"MM") >= 4 THEN CSTR(CINT(Format(Now(),"MM")) - 3)
ELSE CSTR(CINT(Format(Now(),"MM")) + 9) END + "]"
)
,[Date].[Fiscal Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), DESC)
7. Fiscal Months
ORDER(
LASTPERIODS(3, StrToMember("[Date].[Fiscal Time].[Fiscal Year].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN CSTR(CINT(DATEPART("q", Now())) - 1)
ELSE CSTR(CINT(DATEPART("q", Now())) + 3) END + "].&[" +
CASE WHEN CINT(Format(Now(),"MM")) >= 4 THEN Format(Now(), "yyyy")
ELSE CSTR(CINT(Format(Now(), "yyyy")) - 1) END + "]&[" +
CASE WHEN Format(Now(),"MM") >= 4 THEN CSTR(CINT(Format(Now(),"MM")) - 3)
ELSE CSTR(CINT(Format(Now(),"MM")) + 9) END + "]"
)),[Date].[Fiscal Time].CURRENTMEMBER.PROPERTIES("ID", TYPED), DESC)
8. Last Calendar Month
STRTOMEMBER("
[Date].[Time].[Year].&["
+ Format(Now(),"yyyy")
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ cstr(datepart("q", Now()))
+"].&["
+ Format(Now(), "yyyy")
+"]&["
+ Format(Now(),"MM")
+"].PREVMEMBER"
)