Tuesday, July 16, 2019
Saturday, August 31, 2013
How to Load Excel 2007 file in SQL Server 2005 (SSIS 2005)
It is very difficult in a situation that we need to load Excel 2007 file into the database by the use of SQL Server 2005 version (SSIS).
So when the situation comes how to do it. It is very easy, follow the steps below,
I have an excel 2007 file with the some data as shown below,
 I have created a package, where i have dragged a data flow in the control flow pane,
I have created a package, where i have dragged a data flow in the control flow pane,
In the control pane create a variable with name as filename and give the file names,
D:\SAMPLE_EMP.XLSX
On the data flow pane , i have dragged a OLE DB Source and configure as shown below,




So when the situation comes how to do it. It is very easy, follow the steps below,
I have an excel 2007 file with the some data as shown below,
In the control pane create a variable with name as filename and give the file names,
D:\SAMPLE_EMP.XLSX
On the data flow pane , i have dragged a OLE DB Source and configure as shown below,

When you click new connection a window will be opened, select the provider as shown in the above picture, this provider is available if MS office is installed on the machine, if the option not available , download the provider from internet and install it.
On the server name give the file with path as shown above in the picture.

In the left pane , On the ALL tab, write Excel 12.0 as shown in the picture.
Next, Test the connection and if the connection is succeed, we almost succeeded.
Now click okay. Select the sheet which we need to load as shown in the picture below,

Now, Open the connection manager Properties right clicking on it ,
On the properties click the expression and give the variable on the SERVERNAME for the file name
as shown below,

Click okay. why the variable is given on the expression? To load dynamically.
Now can add the destination and run the job, Success.
Hope you like it :)
Tuesday, April 2, 2013
SQL Server Functions - VARP, SOUNDEX and NTILE
SQL Server functions, and
wanting to get a greater understanding of which functions are available
and how they can help improve the efficiency and facility of SQL
routines. Using system functions can help remove unwanted inefficiencies
in code, such as loops, nested loops and string-based field
manipulation. The functions available in SQL Server can tie in well with
business logic, enabling the developer to write better-suited
algorithms to support business requirements.
Functions in SQL Server - one for statistical aggregation (VARP), one for English phonics (SOUNDEX), and one for ranking and grouping (NTILE). It will also provide an overview of the RANK and DENSE_RANK functionality to complement the exploration of NTILE. Hopefully by seeing how useful just a few functions can be, this article will encourage you to find out more about system functions in SQL Server, and at the bottom of the article are a number of links to the Books Online documentation on non-user-defined functions.
As every data professional knows, some functions are used far more than others - commonly SUM and COUNT. However SQL Server ships with a wide variety of different functions, and these can be used in many different contexts. For those of you of a mathematical or statistical persuasion, it may interest you to know that SQL Server supports a wide variety of statistical aggregation and calculation functions, together with a number of mathematical and algebraic functions that can assist in, for example finance calculations, often taking the place of more complex and inefficient code.
Let us now say that we wish to compute the average deviation from the
mean for each city in our test table. That is, we wish to find out how
far away from the average, on average, each temperature reading is
within the appropriate category (location). However, we cannot simply
calculate the deviation by taking each reading and subtracting or adding
the mean, since this will give us a range of values that are mixed
positive and negative and by definition will cancel each other out. We
must instead use a different method of measuring the deviation. There
are three commonly used - absolute deviation, which is the deviation
from the mean with the sign (minus or plus) disregarded; the variance,
in which each deviation is squared to obtain a positive number (be aware
that -x^2 = x^2 for all positive natural numbers x in X) - and standard
deviation, which is simply defined as the average deviation, as
computed by variance (in other words, the square root of the variance).
So to be more precise, variance, mathematically, is defined as the sum of the squared distances of each member of a set of numbers from the mean (average) of that set of numbers, divided by the number of members. So, in the example above, we might wish to know the mean temperature in Moscow based on the information available, and the variance of this set of data as our chosen measure of variation in temperature. Because of the peculiarity of my example having a set of data spread across columns rather than in a single column, we have an opportunity to first UNPIVOT the data then use AVG and VARP to get this information, like so:
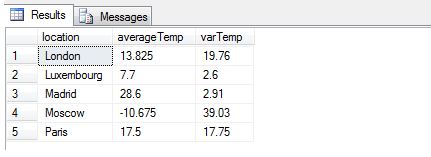 As you can see from this result, it might be better to use STDEV (or
STDEVP) to gain a more accurate measure of the true variance, as 39.03
is clearly a poor figure to indicate variance in degrees Celsius, since
it exceeds the range of values. In statistics, for precisely this
reason, standard deviation is the preferred variance measure as the
square root of the variance provides a linear relationship instead of an
exponential one. It's worth noting that SQL Server exhibits some odd
behavior here - although SQRT(VARP(expression)) is logically equivalent
to STDEVP(expression), interestingly and I suspect due to rounding,
truncation or arithmetic errors to do with SQRT, the two values are NOT
identical when computed in SQL Server - they vary by a small amount.
As you can see from this result, it might be better to use STDEV (or
STDEVP) to gain a more accurate measure of the true variance, as 39.03
is clearly a poor figure to indicate variance in degrees Celsius, since
it exceeds the range of values. In statistics, for precisely this
reason, standard deviation is the preferred variance measure as the
square root of the variance provides a linear relationship instead of an
exponential one. It's worth noting that SQL Server exhibits some odd
behavior here - although SQRT(VARP(expression)) is logically equivalent
to STDEVP(expression), interestingly and I suspect due to rounding,
truncation or arithmetic errors to do with SQRT, the two values are NOT
identical when computed in SQL Server - they vary by a small amount.
Variance still has its uses in mathematical circles, for example when working out the total variance of uncorrelated variables, and other matters familiar to those versed in discrete probability theory. For example, one may wish to identify statistical outliers in the temperature information given - if we had a hundred different readings and knew that the typical verified variance is approximately 39deg for Moscow, any figure significantly different from this would raise alarm bells. Standard deviation would not do, since the differences are linear and may be missed when statistically aggregating the individual variances as the difference between the expected and actual standard deviations would be too small - whereas the exponential nature of variance, obtained using VARP, would quickly distort the 39deg figure into an unlikely number, rendering it identifiable to the statistical researcher.
A good use of Soundex could be to assist in the automatic detection of fraud. Some time ago, I used to work as a database administrator for a small company specializing in the provision of online gambling to US customers. This company would use a number of weighted measures built as stored procedures which would take many different factors, from postcode to IP address to demographic, to make an intelligent decision on whether a new customer signup was likely a duplicate of an existing account, in order to help prevent fraud. Although SOUNDEX wasn't used in this context, there would have been a strong case for inclusion as a fuzzy matching algorithm to determine the similarity of the 'John Smith's to the 'Johann Smythe's.
In summary, Soundex is a specification originally designed in 1918 by Robert C. Russell and Margaret Odell, and has risen to prominence in a number of database specifications as a preferred system for categorizing and relating phonics. For the history of Soundex and for a more detailed description of the variants in use today, see the links at the bottom of the page for more information.
Example of using Soundex:
 We could implement a SOUNDEX-based system to identify
similarly-sounding names and write a stored procedure which will
identify customer records based on matching phonics. Here's a brief
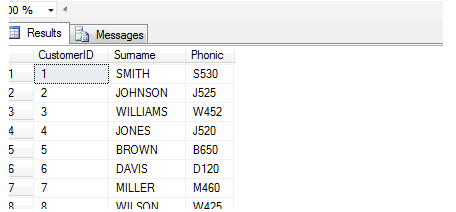
example of how it could work. Below is the build code to generate a
table with customer ID, surname and SOUNDEX code for 1000 common
surnames (you can find the list attached to this article as sample_name_data.txt):
We could implement a SOUNDEX-based system to identify
similarly-sounding names and write a stored procedure which will
identify customer records based on matching phonics. Here's a brief
example of how it could work. Below is the build code to generate a
table with customer ID, surname and SOUNDEX code for 1000 common
surnames (you can find the list attached to this article as sample_name_data.txt):
 Now you could write a stored procedure to find names with similar sounds, like so:
Now you could write a stored procedure to find names with similar sounds, like so:
We test it like this:
With this result:
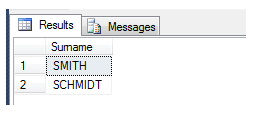 As you can see, with some development a powerful phonics comparison system can easily be built.
As you can see, with some development a powerful phonics comparison system can easily be built.
Consider the following (fictional) horrible and inefficient piece of
code to rank customers in a table by £ (or $) amount gambled.
As you can see, this is inefficient and bulky. It pre-separates out
the source data into the distinct classes, orders the contents of those
classes by TotalDeposited, and glues them back together in a results
table. The output is identical to this slimline version using RANK():
As you can see, this is easier to read. It doesn't use a cursor and
the sorting and ordering are taken care of internally. If you're unused
to ranking functions, note that PARTITION BY x means 'partition each set
of ranks by distinct x' and ORDER BY x determines the order in which
the values must be ranked. So in the example above, PARTITION BY
CustomerClass means 'return ranks from 1 to N for each distinct class
(gold, silver, bronze)' and ORDER BY TotalDeposited DESC means '... and
the ranking should run from largest to smallest.'
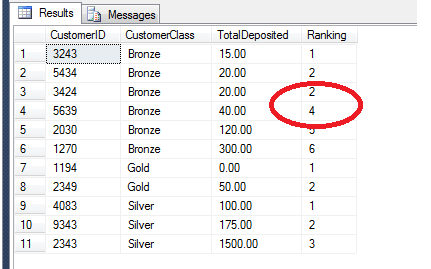
This will insert another row with the TotalDeposited value at 20.00,
which means it will tie-break with the row with CustomerID 5434 as seen
below:
We can avoid this by using DENSE_RANK as follows:
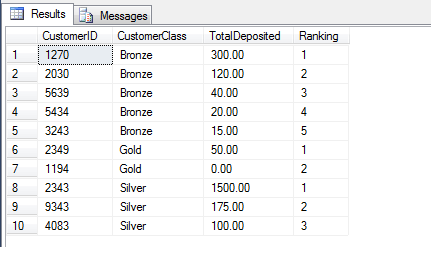
 In the above example, we have taken all values irrespective of player
class and returned them in the specified order, arranged into
evenly-distributed groups. We may therefore use this data to say,
'Players 1194, 3243 and 5434 are in the top 25% of players who have
contributed the most money to our enterprise'. This function is very
useful when e.g. computing performance on a bell curve
(evenly-distributed curve). The definition according to BOL may make
more sense here:
In the above example, we have taken all values irrespective of player
class and returned them in the specified order, arranged into
evenly-distributed groups. We may therefore use this data to say,
'Players 1194, 3243 and 5434 are in the top 25% of players who have
contributed the most money to our enterprise'. This function is very
useful when e.g. computing performance on a bell curve
(evenly-distributed curve). The definition according to BOL may make
more sense here:
Functions in SQL Server - one for statistical aggregation (VARP), one for English phonics (SOUNDEX), and one for ranking and grouping (NTILE). It will also provide an overview of the RANK and DENSE_RANK functionality to complement the exploration of NTILE. Hopefully by seeing how useful just a few functions can be, this article will encourage you to find out more about system functions in SQL Server, and at the bottom of the article are a number of links to the Books Online documentation on non-user-defined functions.
As every data professional knows, some functions are used far more than others - commonly SUM and COUNT. However SQL Server ships with a wide variety of different functions, and these can be used in many different contexts. For those of you of a mathematical or statistical persuasion, it may interest you to know that SQL Server supports a wide variety of statistical aggregation and calculation functions, together with a number of mathematical and algebraic functions that can assist in, for example finance calculations, often taking the place of more complex and inefficient code.
VARP
Consider the following example to calculate the variance of a set of temperature values. Here we first define a test table with some temperature readings taken on different occasions for some major cities:CREATE TABLE dbo.temperatureTable ( uqid INT IDENTITY(1,1) PRIMARY KEY NOT NULL, location VARCHAR(10), locationCode TINYINT, TemperatureA FLOAT, TemperatureB FLOAT, TemperatureC FLOAT, TemperatureD FLOAT ) INSERT INTO dbo.temperatureTable ( location, locationCode, TemperatureA, TemperatureB, TemperatureC, TemperatureD ) VALUES ( 'London', 3, 19.6, 8.2, 16.4, 11.1 ), ( 'Paris', 7, 10.5, 20.2, 21.3, 18.0 ), ( 'Madrid', 4, 31.1, 28.3, 26.3, 28.7 ), ( 'Moscow', 9, -13.5, -12.0, -16.9, -0.3), ( 'Luxembourg', 6, 8.3, 5.5, 7.1, 9.9 )
So to be more precise, variance, mathematically, is defined as the sum of the squared distances of each member of a set of numbers from the mean (average) of that set of numbers, divided by the number of members. So, in the example above, we might wish to know the mean temperature in Moscow based on the information available, and the variance of this set of data as our chosen measure of variation in temperature. Because of the peculiarity of my example having a set of data spread across columns rather than in a single column, we have an opportunity to first UNPIVOT the data then use AVG and VARP to get this information, like so:
SELECT location, AVG(Temperature) [averageTemp], ROUND(VARP(Temperature),2) [varTemp] FROM ( SELECT location, TemperatureA, TemperatureB, TemperatureC, TemperatureD FROM dbo.temperatureTable ) p UNPIVOT ( Temperature FOR City IN ( TemperatureA, TemperatureB, TemperatureC, TemperatureD ) ) AS u GROUP BY location
Variance still has its uses in mathematical circles, for example when working out the total variance of uncorrelated variables, and other matters familiar to those versed in discrete probability theory. For example, one may wish to identify statistical outliers in the temperature information given - if we had a hundred different readings and knew that the typical verified variance is approximately 39deg for Moscow, any figure significantly different from this would raise alarm bells. Standard deviation would not do, since the differences are linear and may be missed when statistically aggregating the individual variances as the difference between the expected and actual standard deviations would be too small - whereas the exponential nature of variance, obtained using VARP, would quickly distort the 39deg figure into an unlikely number, rendering it identifiable to the statistical researcher.
SOUNDEX
Moving away from statistics, the SOUNDEX function is an interesting example of a function that exclusively implements a third-party specification, a proprietary algorithm developed and patented privately nearly a hundred years ago. SOUNDEX is a function built by Microsoft to a precise algorithmic specification. The Soundex specification is designed for use in systems where words need to be grouped by phonic sound rather than by spelling - for example, in ancestry and genealogy, the surnames Smith, Smyth and Smithe are spelled differently but could be pronounced the same. It is important for users of expert systems that deal in phonics to be able to recognize these similarities without complex and inefficient rule based systems to slow down the storage and retrieval process.A good use of Soundex could be to assist in the automatic detection of fraud. Some time ago, I used to work as a database administrator for a small company specializing in the provision of online gambling to US customers. This company would use a number of weighted measures built as stored procedures which would take many different factors, from postcode to IP address to demographic, to make an intelligent decision on whether a new customer signup was likely a duplicate of an existing account, in order to help prevent fraud. Although SOUNDEX wasn't used in this context, there would have been a strong case for inclusion as a fuzzy matching algorithm to determine the similarity of the 'John Smith's to the 'Johann Smythe's.
In summary, Soundex is a specification originally designed in 1918 by Robert C. Russell and Margaret Odell, and has risen to prominence in a number of database specifications as a preferred system for categorizing and relating phonics. For the history of Soundex and for a more detailed description of the variants in use today, see the links at the bottom of the page for more information.
Example of using Soundex:
SELECT SOUNDEX('David'), SOUNDEX('Johnson'), SOUNDEX('Alison')
CREATE TABLE dbo.SoundexTest ( CustomerID INT IDENTITY(1,1) PRIMARY KEY NOT NULL, Surname VARCHAR(20), Phonic VARCHAR(10) ) CREATE TABLE #surnames ( Surname VARCHAR(20) ) BULK INSERT #surnames FROM N'c:\del\mssqltips_190213_final\sample_name_data.txt' -- replace with your path & file INSERT INTO dbo.SoundexTest (Surname, Phonic) SELECT Surname, SOUNDEX(Surname) FROM #surnames SELECT * FROM dbo.SoundexTest
CREATE PROCEDURE dbo.checkSimilarNames ( @surname VARCHAR(20) )
AS BEGIN
DECLARE @phonic VARCHAR(10)
SET @phonic = ( SELECT TOP 1 Phonic
FROM dbo.SoundexTest
WHERE Surname = @surname )
IF @phonic IS NULL
RAISERROR('Surname not found!',10,1)
ELSE
BEGIN
SELECT Surname
FROM dbo.SoundexTest
WHERE Phonic = @phonic
END
END
EXEC dbo.checkSimilarNames @surname = 'SMITH'
RANKING FUNCTIONS
The final section of this article will deal with ranking functions, which includes the RANK, DENSE_RANK and NTILE functions and in the author's humble opinion, underused in most SQL Server database implementations. As a database administrator, much of my job involves reviewing and correcting code, examining existing SQL schemas, procedures and functions, and improving performance wherever possible. Given the usefulness of RANK, DENSE_RANK and NTILE, I am surprised that (at least in my experience) ranking functions are not used more often.RANK
I have included the table build code below for your convenience:CREATE TABLE [dbo].[rankingTable]( [CustomerID] [int] NOT NULL, [CustomerClass] [varchar](6) NULL, [TotalDeposited] [money] NULL, [TotalWithdrawn] [money] NULL, [CurrentBalance] [money] NULL, UNIQUE NONCLUSTERED ( [CustomerID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO INSERT INTO dbo.RankingTable (CustomerID, CustomerClass, TotalDeposited, TotalWithdrawn, CurrentBalance) SELECT 1270, 'Bronze', 300.00, 0.00, 285.00 UNION ALL SELECT 3243, 'Bronze', 15.00, 0.00, 122.00 UNION ALL SELECT 4083, 'Silver', 100.00, 25.00, 255.00 UNION ALL SELECT 2349, 'Gold', 50.00, 0.00, 47.00 UNION ALL SELECT 9343, 'Silver', 175.00, 50.00, 22.00 UNION ALL SELECT 5434, 'Bronze', 20.00, 0.00, 0.00 UNION ALL SELECT 2343, 'Silver', 1500.00, 500.00, 134.00 UNION ALL SELECT 1194, 'Gold', 0.00, 0.00, 0.00 UNION ALL SELECT 5639, 'Bronze', 40.00, 10.00, 95.00 UNION ALL SELECT 2030, 'Bronze', 120.00, 0.00, 105.00 UNION ALL SELECT 3424, 'Bronze', 20.00, 0.00, 5.00 GO
DECLARE cur_ForEachClass CURSOR LOCAL FAST_FORWARD
FOR SELECT DISTINCT CustomerClass
FROM dbo.rankingTable rt
DECLARE @class VARCHAR(6)
OPEN cur_ForEachClass
FETCH NEXT FROM cur_ForEachClass INTO @class
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO @resultsTable
SELECT CustomerID, CustomerClass, TotalDeposited,
ROW_NUMBER() OVER ( ORDER BY TotalDeposited DESC ) [Ranking]
FROM dbo.rankingTable
WHERE @class = CustomerClass
FETCH NEXT FROM cur_ForEachClass INTO @class
END
SELECT * FROM @resultsTable
SELECT CustomerID, CustomerClass, TotalDeposited, RANK() OVER (PARTITION BY CustomerClass ORDER BY TotalDeposited ) AS [Ranking] FROM dbo.rankingTable
DENSE_RANK
DENSE_RANK is the second main ranking function and is similar to RANK except that gaps in the ranking are not allowed. In essence, when there is a tie-break in the conditions for the RANK then the ranking 'skips' one value and continues on. DENSE_RANK does not do this but continues immediately after the tie. This is illustrated by adding another line to our example:INSERT INTO dbo.rankingTable VALUES ( 3424, 'Bronze', 20.00, 0.00, 5.00 );
SELECT CustomerID, CustomerClass, TotalDeposited, RANK() OVER (PARTITION BY CustomerClass ORDER BY TotalDeposited ) AS [Ranking] FROM dbo.rankingTable
SELECT CustomerID, CustomerClass, TotalDeposited, RANK() OVER (PARTITION BY CustomerClass ORDER BY TotalDeposited ) AS [Ranking] FROM dbo.rankingTable
NTILE
This brings us nicely onto NTILE. Think of NTILE as 'N'-TILE where N refers to the 'segments' of the whole, in the same sense of the words QUARTile or PERCENTile. This is how to use it:SELECT CustomerID, TotalDeposited, NTILE(4) OVER (ORDER BY TotalDeposited) AS [Quartile] FROM dbo.rankingTable
NTILE can therefore be useful when, for example, creating procedures that execute groups of statements in batch, or when you wish to aggregate financial figures.
Wednesday, May 30, 2012
Extracting Data From Multiple Excel Files Having Multiple Data Sheets
Let us consider the
case where there is number of MS-Excel files and each files have a
number of sheets in them. And we have to export all these data to a
common repository.
To accomplish this task we will use For Each Loop Container to load all these Excel sheet data.
Below are the steps that need to be followed to achieve this task through SSIS.Step 1: Create a new SSIS Package and Rename it to “Export Dynamic Excel File with Multiple Sheets.dtsx”
Step 2: Create Connection Manager for Source (Excel Connection Manager). Perform the following task:
To accomplish this task we will use For Each Loop Container to load all these Excel sheet data.
Below are the steps that need to be followed to achieve this task through SSIS.Step 1: Create a new SSIS Package and Rename it to “Export Dynamic Excel File with Multiple Sheets.dtsx”
Step 2: Create Connection Manager for Source (Excel Connection Manager). Perform the following task:
- Right click on the Connection Managers pane and choose “New Connection…” from context menu, Select “EXCEL” and click “Add” the “Excel Connection Manager” window will be opened.
- On Excel Connection Settings Pane specify any one of the excel file name among all other files that need to be exported.
- Check the checkbox that says “First rows has a column name”
- Rename this Connection manager as “Excel Connection Manager - Source”.

Fig 1: Excel File structure needs to be exported.
The
below figure (Fig 2) shows the Data in Excel sheet of file AU.xls.
AU.xls file has 2 sheets in it and similarly all other excel files in
above figure have 2 or more sheets in them. So we have to export the
data present in various sheets of above 4 Excel files shown in Fig 1.

Fig 2: Excel Sheet Structure
Step 3: Create a variable named “CurrentExcelSheet” of String type with the default value “Queensland$” Which is one of the Sheet name in the above Excel File. By default Excel File has sheet1, sheet2 and sheet3 in it. So Provide the proper sheet name which must exists in the specified Connection Manger Excel File. In this sample example the Excel Manger is set to "AU.xls" and "Queensland" is one of the sheets of Excel file “AU.xls”. It contains 2 sheets in it and I have specified one of them. If specified Sheet name does not exist then it will through an error.
Step 4: Drag and drop “Foreach Loop Container” in Control Flow area. Set the properties as follows:
- General: Change the Name to “Foreach Loop Container- Excel File Iterator”.
- Collection: Set the “Enumerator” in Collection pane to Foreach File Enumerator. Refer to Figure 3.
In addition to this make the following Enumerator Configuration settings:- Folder: Specify the Folder path where all the excel files are stored which has to be exported to the common repository. Here the folder path specified is same as shown in Figure 1 (address bar).
- Files: Specify the file
name as “*.xls” which will limits to excel files only and will not go to
read any other file type even if they are present in the specified
folder. We can specify "*.*" here, if we are very much sure that all the files must be of ".xls" type.
Fig 3: Foreach File Enumerator Configuration
- Variable Mappings: Map the
file name to a particular variable. So that on each iteration different
files will be assigned to this variable. So, in drop down click <New Variable…>, a new window “Add variable” will be open and declare the variable as “FileName”. In “Value”
textbox specify (Fig: 5) the full path of one of the excel file that
has to exported which will be the default value for this variable.
Fig 4: Foreach loop Enumerator Variable Mapping
Fig 5: Add Variable



And finally click “OK” to close the Add variable window. Variable Mapping tab will look like below after configuration. Set the Index of this variable to 0.

Fig 6: Variable Mapping
The added “Foreach Loop Container” Will iterate through each excel files placed in the folder (the folder path specified on Collection tab above). Now, On each iteration a new file name will be assigned to the variable but at the same time we need to iterate through all the Excel sheets present in the assigned Excel File to extract the data. So, to iterate through each excel Sheets of the selected Excel file we will take another “Foreach Loop Container”.
Step 5: Drag and drop another Foreach Loop Container and place it inside the Existing “Foreach Loop Container – Excel File Iterator”. The below figure shows 2 Foreach Loop Container paced one inside another. The Outer Foreach Loop Container will iterate through the Excel Files and the inner will iterate through the available Sheets of the selected Excel file hold by the outer Foreach Loop container.

Fig 7: Package Layout
- General: Rename it to Foreach Loop Container - Iterate through Excel Sheet.
- Collection: Set the “Enumerator” in Collection pane to Foreach ADO.NET Schema Rowset Enumerator. In addition to this make the following Enumerator Configuration:

Fig 8: Foreach ADO.NET Schema Rowset Enumerator
Connection: Create a new connection of type ADO.NET Connection. Click “New Connection…” to open the connection Manager window.The value “Excel 8.0” for Extended Properties is specified to Excel 97-2003 files. If you are dealing with Excel 2007 file you need to use “Excel 12.0” in Extended properties.
Connection Manager: Make the following configuration on Connection Manager Window
Provider: Microsoft Jet 4.0 OLEDB Provider as shown in figure 10.
DataBase file name: Specify the Database file name which is the path of the excel file. So specify the full path of one of the Excel file that has to be exported to common repository. Leave the user name and password textbox as it is.
All: Click All (Figure 9) and Set the Extended properties as follows:
Fig 9: Connection Manager
Fig 10: Advanced setting for Excel Connection


Test the connection and close the connection manager. The connection Manager will look like figure 11.

Fig 11: Connection Manager Window
Rename the newly created ADO.NET connection as ADO.NET Connection for Excel. Make sure that this newly created ADO.NET Connection for Excel is selected in the Connection dropdown of Collection Tab shown in figure 8.
Schema: In Schema dropdown select Table.
- Variable Mappings: We
have created the variable in Step3 CurrentExcelSheet. Set variable name
as CurrentExcelSheet and under index mention 2. 2 here hold the index
value which will hold the table name so in case of excel it will be the
Excel Sheet name. The Excel Sheet will be assigned to this variable.
Fig 12: Foreach Loop Variable Mapping

Step 6: The “Excel Connection manager – Source” created in Step2 has to me modified as we have to iterate through each of the excel files specified in the folder. To make this connection dynamic go to the Properties Window of the “Excel Connection Manger – Source” and select “Expression” (shown in figure 13) and on the button click to open Property Expression Editor. Under "Property" dropdown choose “ConnectionString” and click the ellipse Button right of the “Expression” textbox to write the expression for it.

Fig 13: Property Expression
"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + @[User::FileName] +";Extended Properties=\"Excel 8.0;HDR=YES\";"
Click “Evaluate Expression” button to evaluate the expression written for the ConnectionString. Click “OK” to close the Expression window.

Fig 14: Expression Builder
Here the @[User::FileName] is the variable created to hold the name of Excel file. So on each iteration a new excel file will be assigned and hence it will hold dynamic value in it.
Step 7: We have already created the Connection manager (ADO.NET Connection for Excel) for ADO.Net while configuring the “Foreach Loop Container - Iterate through Excel Sheet”. Remember that we have specified the Physical path for the “ADO.Net Connection for Excel” connection manager. Since we have to loop through the excel sheets of the select excel file we have to make the connection dynamic so that on each iteration a new Excel Sheet file is allocated to this connection manager.So we will make the dynamic connection for the “ADO.NET Connection for Excel”. To do this we will repeat the same process that we have done in Step 6 for the dynamic connection string. This will also have the same line of Expression as:
"Provider=Microsoft.Jet.OLEDB.4.0;Data Source="+ @[User::FileName] +";Extended Properties=\"Excel 8.0;HDR=YES\";"
This will make the connection dynamic for ADO.NET Connection for Excel.
Step 8: Now Drag and Drop the Data Flow Task inside the “Foreach Loop Container - Iterate through Excel Sheet”. Double click Data Flow Task and will navigate to “Data Flow” tab.
Step 9: Drag and drop the “Excel Source”. Make the configuration as specified in the below figure.
Data access mode- In Data access mode dropdown select Table name or view name variable as shown in Figure 15. Since on each iteration the table name (here Excel sheet) is being assigned from a variable.
Variable name- Specify the name of variable which holds the name of Excel sheets and not the Excel file names.

Fig 15: Excel Source Editor
Click on the “Columns” tab to check whether the Columns Names specified are reflected or not. Click “OK” to close this window.
The source connection manager will pull the data from the Excel source that we have specified earlier. Now we will take another excel file as destination where all the data from various excel files having multiple sheets will be pushed into.
Step 10: Now we are going to hold all the data being extracted from Source to another Excel file. So we have to create a separate Excel Connection manager for the destination and name it to “Excel Connection Manager”.
Step 11: Drag and Drop “Excel Destination” on Data Flow. Extend the Green arrow of “Excel Source” created in Step 9 and attach to the “Excel Destination”. Make following Configuration:
Data access mode- Remember here Data access mode is set to Table or View. Here the data is being sent to a particular table which will hold the data from various sheets of excel files.

Fig 16: Excel Destination Editor
- Connection Manager: Specify the Destination connection manager create din step 10 under OLEDB Connection Manager.
- Data Access mode: Set to Table or View
- Name of the Excel Sheet: Click on New to create new table or select existing table from dropdown.
Fig 17: Create Table
- Mappings: Map the Columns of source to Destination.


Fig 18: Package Execution
Conclusion: We have extracted the data from the excel sheet and placed them to the excel destination as final data. We can take different destination to hold the data, only we need to change the destination connection String. So, you can play with the data stored in the number of excel files having excel sheets in it and see how it works.
Tuesday, May 29, 2012
SSIS-Logging
When working with designing and developing ETL processes, one of the
important aspects that needs to factored in is the auditing of the ETL
process. It is very important to keep track of the flow of process with
in ETL. While working with SSIS, it is important to design auditing
feature for a SSIS package. There are several ways of auditing SSIS
packages:
1: To use the SQL Jobs history to figure out if there was an error in the SSIS job step and then troubleshoot the problem. This might not effective way to audit.
2: The other option would be is to create an audit table with in a sql server database and keep inserting records into his table at he beginning and completion of each step.
This could be tedious, since there could be lot of calls to the same stored procedure using multiple execute sql tasks.
One a new SSIS package is being created, SSIS itself provides logging capabilities. The logging option can be seen by right clicking anywhere on the design surface of the SSIS package. When you click on the logging option, the following window pops up, there will be SSIS package and the various tasks in SSIS package on the left. On the right hand side within the window you have two tabs Providers and Logs, Details. When you choose the Provider type there are different types available:
 SSIS log provider for SQL Server,
SSIS log provider for SQL Server,
SSIS log provider for Windows Event Log
SSIS log provider for XML Files
SSIS log provider for Text Files
SSIS log provider for Sql Server Profiler
I choose the SSIS log provider for SQL Server, Once this is done check the box next to the option SSIS log provider for SQL Server, then choose the database connection where the logging will happen, when SSIS package runs it creates a table called sysssislog. In the details tab, choose the Events that need to be tracked, look at the figure below for reference.
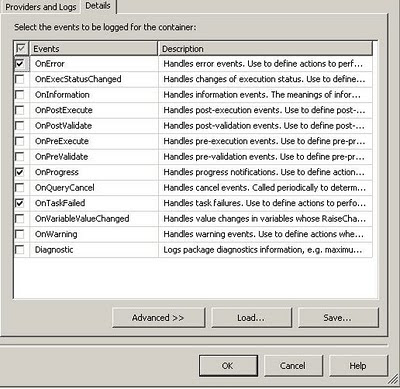 Once this is done, click the OK button, Logging is now enabled for the
SSIS package. Once the package is executed, look for the table
sysssislog in the System databases under the database which was chosen
in the Configuration column in the Provider and Logs tab. The sysssislog
table has columns called source (contains the name of each task which
is executed), message which contains more detailed message about the
task,event (which contains the event that were chosen to be audited).
The table also has columns called starttime and endtime which indicates
the start and end time of each task.
Once this is done, click the OK button, Logging is now enabled for the
SSIS package. Once the package is executed, look for the table
sysssislog in the System databases under the database which was chosen
in the Configuration column in the Provider and Logs tab. The sysssislog
table has columns called source (contains the name of each task which
is executed), message which contains more detailed message about the
task,event (which contains the event that were chosen to be audited).
The table also has columns called starttime and endtime which indicates
the start and end time of each task.
SELECT * FROM dbo.sysssislog
To summarise, using the Logging option in SSIS, one can audit SSIS packages very effectively
1: To use the SQL Jobs history to figure out if there was an error in the SSIS job step and then troubleshoot the problem. This might not effective way to audit.
2: The other option would be is to create an audit table with in a sql server database and keep inserting records into his table at he beginning and completion of each step.
This could be tedious, since there could be lot of calls to the same stored procedure using multiple execute sql tasks.
One a new SSIS package is being created, SSIS itself provides logging capabilities. The logging option can be seen by right clicking anywhere on the design surface of the SSIS package. When you click on the logging option, the following window pops up, there will be SSIS package and the various tasks in SSIS package on the left. On the right hand side within the window you have two tabs Providers and Logs, Details. When you choose the Provider type there are different types available:

SSIS log provider for Windows Event Log
SSIS log provider for XML Files
SSIS log provider for Text Files
SSIS log provider for Sql Server Profiler
I choose the SSIS log provider for SQL Server, Once this is done check the box next to the option SSIS log provider for SQL Server, then choose the database connection where the logging will happen, when SSIS package runs it creates a table called sysssislog. In the details tab, choose the Events that need to be tracked, look at the figure below for reference.

SELECT * FROM dbo.sysssislog
To summarise, using the Logging option in SSIS, one can audit SSIS packages very effectively
Monday, May 28, 2012
SSIS Documentation
One of the important tasks when there are ETL SSIS packages being
developed for a Data Mart/Datawarehouse project is ability to document
the SSIS packages. It is sometimes very time consuming to open package
by package and then go through all the tasks to understand what is being
done in the package. The other issues here is that there is a
dependency on Visual studio being present on the laptop/PC. One of the
products available to perform this type of task is called
SSIS Documenter, this product supports both SSIS 2005 and SSIS 2008. The
product can be downloaded from the website:
http://www.ssisdocumenter.com/
The documentation can be done either in online or can download documenter and install to use with SSIS packages.
Once the product is downloaded, the installation is very straightforward. When the installation is complete in case BIDS/Visual studio is already open, save the work and exit out of VS/BIDS. Reopen Visual Studio/BIDS, open up the SSIS project/solution or the package. In the Solution explorer, right click on the SSIS package that requires documentation and once can see the Generate Documentation Option. Please see image below:
 Click on the option, once the document is finished, a folder called
Documentation is created and in the folder one can see the package
documentation with a .html extension. The neat thing about the .html
option is that the documentation can be viewed in a browser. Right click
on the .html like shown in the image below and choose view in browser,
the documentation will open up in the browser.
Click on the option, once the document is finished, a folder called
Documentation is created and in the folder one can see the package
documentation with a .html extension. The neat thing about the .html
option is that the documentation can be viewed in a browser. Right click
on the .html like shown in the image below and choose view in browser,
the documentation will open up in the browser.

There are 2 types of documentation available Brief/Verbose. Each of the task in the SSIS package is depicted in a diagram and one can click on any task, then it takes you detail of the task. The script/sql statements are depicted in a neat way like an editor and once can copy the script/sql statements to the clipboard or any other tool to examine the statements. The documentation tool is very helpful for developers,architects and support folks who need to analyse the package and understand the flow of data from source to destination. This type of SSIS documentation can greatly enhance the stability of an ETL group and in cases where folks leave, it would be very helpful for developers who are coming on board to the team. Snapshot of the documentation below:
http://www.ssisdocumenter.com/
The documentation can be done either in online or can download documenter and install to use with SSIS packages.
Once the product is downloaded, the installation is very straightforward. When the installation is complete in case BIDS/Visual studio is already open, save the work and exit out of VS/BIDS. Reopen Visual Studio/BIDS, open up the SSIS project/solution or the package. In the Solution explorer, right click on the SSIS package that requires documentation and once can see the Generate Documentation Option. Please see image below:
There are 2 types of documentation available Brief/Verbose. Each of the task in the SSIS package is depicted in a diagram and one can click on any task, then it takes you detail of the task. The script/sql statements are depicted in a neat way like an editor and once can copy the script/sql statements to the clipboard or any other tool to examine the statements. The documentation tool is very helpful for developers,architects and support folks who need to analyse the package and understand the flow of data from source to destination. This type of SSIS documentation can greatly enhance the stability of an ETL group and in cases where folks leave, it would be very helpful for developers who are coming on board to the team. Snapshot of the documentation below:

SQL Server 2012 (Ebook)
There are some free ebooks available from Microsoft press, some of the
ebooks include SQL Server 2012 Introduction and SQL Server 2008 R2
Introduction. I downloaded the SQL Server 2012 ebook which was around 10
MB pdf file. The content was good in the sense of providing what are
the new features available in SQL Server 2012, the book covers from
Database Administration to Reporting services. The book is divided into
two main parts Database and Administration, the Second part being
Business Intelligence. The material is extensive in the sense that the
content is not merely a bullet list of issues. Below is the link
provided, I would like to that the SQLServerCentral.com for providing
the links.
http://blogs.msdn.com/b/microsoft_press/archive/2012/05/04/free-ebooks-great-content-from-microsoft-press-that-won-t-cost-you-a-penny.aspx
Hope you guys enjoy the ebooks.
http://blogs.msdn.com/b/microsoft_press/archive/2012/05/04/free-ebooks-great-content-from-microsoft-press-that-won-t-cost-you-a-penny.aspx
Hope you guys enjoy the ebooks.
Subscribe to:
Comments (Atom)